

Stable Diffusion 危険性を調べている方は、その便利さの裏側に潜むリスクや、安全に利用できる範囲を知りたいと考えているでしょう。本記事では、まずStable Diffusionとは何かという基本から出発し、Stable Diffusionの意味やStable Diffusion 原理、さらに研究で示されるStable Diffusion 理論までをわかりやすく解説します。
そのうえで、Stable Diffusion web ui 危険性として指摘されるプラグイン導入時の感染リスクや外部公開設定の注意点、Stable Diffusion 安全性を高めるための設定と運用方法、Stable Diffusion 無料 使用料の仕組みやモデル選定のポイント、さらにStable Diffusion 弱点に起因する誤生成やバイアスの問題について整理します。
また、サービス提供側が定めるStable Diffusion 利用規約や各国で進むStable Diffusion 規制の動向も平易に説明し、利用者が守るべき基準を明確にします。もしStable Diffusion開かないといった起動エラーに直面している場合でも、代表的な症状とその解決手順をまとめています。最終的に、Stable Diffusion 危険性が具体的にどこにあるのかを理解し、安全に活用するための現実的な行動指針を得られる内容になっています。
・Stable Diffusion 危険性の全体像と発生しやすい場面
・法的リスクと利用規約や規制の要点
・WebUIとローカル運用それぞれの安全対策
・代表的な起動エラーと実践的な解決手順
Stable Diffusion 危険性を徹底解説
●このセクションで扱うトピック
- Stable Diffusionとは初心者向け解説
- 原理をわかりやすく解説
- Stable Diffusionは無料?使用料の仕組み
- 弱点とリスクの実態
- どこが危険かを分析
Stable Diffusionとは初心者向け解説

Stable Diffusionとは、テキスト入力から高品質な画像を自動生成できるオープンソースの画像生成AIモデルです。開発したのはStability AIを中心とする研究チームで、2022年に初めて公開されました。特徴は、高性能な生成能力を持ちながらもローカルPCにインストールして利用できる点にあります。
従来の画像生成AIは大規模GPU環境を必要とすることが多かったのに対し、Stable Diffusionは潜在拡散モデル(Latent Diffusion Model)の仕組みを採用することで計算効率を大幅に改善し、比較的入手しやすいGPUでも実用的な画像生成が可能となりました。
このモデルはオープンソースとして公開されており、誰でも自由に導入・改変できる柔軟性を備えています。公式の学習済みモデルをそのまま利用することもできますが、ユーザーは追加の学習(LoRAやDreamBoothなど)を行うことで、自分好みのスタイルや特定のキャラクターを再現できるようにカスタマイズできます。
さらに、拡張機能やユーザーインターフェース(例:Stable Diffusion WebUI)の普及により、プログラミングに詳しくない利用者でも直感的に操作できる点も広く普及した理由のひとつです。
実際の利用シーンは多岐にわたります。イラスト制作、広告やデザインのモックアップ、建築や工業製品のビジュアライゼーション、教育資料や研究分野におけるビジュアル生成など、クリエイティブから実務的用途まで幅広く活用されています。
テキストから高品質な画像を生成できる点に加え、ローカルPCで動かせる実行性、モデルや拡張機能(LoRA、VAE、ControlNetなど)の差し替えによる表現の調整力が評価されています。学習済みモデルやLoRAを適切に組み合わせることで、イラスト調、写真風、線画、3Dレンダー風、建築ビジュアライゼーション、製品モックまで、用途に応じたスタイルに寄せられます。
プロンプト(指示文)とネガティブプロンプト(除外指示)の両輪で要素を制御し、サンプリングアルゴリズム(Euler、DPM++など)やステップ数、CFGスケールなどのパラメータで質と速度のバランスを最適化します。
ローカル運用では、GPUのVRAM容量が体験を左右します。一般的な目安として、512×512px程度の生成なら8〜10GB、より高解像度(768px以上)や高品質設定では12GB以上が現実的です。バッチ生成や動画拡張(img2imgでフレーム変換)を行う場合は24GB級が安定しやすく、SDXL系モデルではさらに余裕があると快適です。クラウド型やオンラインサービスを使う選択肢もあり、初期投資は抑えられる一方、無料枠の回数制限や解像度制限、混雑時の待機が発生することがあります。
運用方法ごとの特徴は次の観点で整理できます。
| 運用形態 | 初期費用 | カスタマイズ性 | セキュリティ/プライバシー | 維持コスト | 想定リスク例 |
|---|---|---|---|---|---|
| ローカルPC | 中〜高 | 非常に高い | 端末内完結で高い | 電力・GPU劣化 | 非公式拡張の混入、依存破損 |
| クラウド(GPUノートブック等) | 低 | 高い | サービス側管理 | 時間課金 | 規約違反時の停止、ストレージ消去 |
| 完全オンライン(Webサービス) | 低 | 低〜中 | 事業者依存 | 月額/従量 | 無断公開範囲の誤設定、回数制限 |
公開や商用利用では、権利・倫理・安全の三点が判断軸になります。既存作品やキャラクター、ロゴ、実在人物に近似する表現が生成されうるため、出力の独自性や参照元の有無を検討し、商用可否・クレジット表記・再配布可否などモデルやLoRAごとのライセンス条項を確認します。
成人向けや暴力描写、未成年を想起させる可能性のある内容は、プラットフォーム規約で強く制限されることがあり、アカウント停止や投稿削除が実務上のリスクです。プロジェクト単位で「使用モデル一覧」「版数」「生成パラメータ」「公開先と規約要件」を記録しておくと、後日の説明責任に応えやすくなります。
最後に、導入初期のつまずきを減らす観点として、以下を押さえると安定します。Pythonと依存関係の固定(推奨バージョンの採用)、GPUドライバとランタイム(CUDA/cuDNN)の整合、モデルはSafeTensor形式の信頼配布元から取得、WebUIの外部公開はデフォルトで無効化、そして生成ログの保存です。これらの基本整備だけでも、安全性と再現性は大きく高まります。
>>>Stable DiffusionのWeb siteはこちらから
●用語補足解説
- LoRA(Low-Rank Adaptation)
学習済みモデルに追加の学習情報を効率的に注入する技術。少量の学習で新しいスタイルや要素を再現できる拡張方式。 - VAE(Variational Autoencoder)
画像を潜在表現に圧縮したり、潜在表現から画像を復元したりする仕組み。生成画像の鮮明さや色合いに影響する。 - ControlNet
入力画像のポーズや輪郭、構造を保持しつつ生成を制御する拡張。ポーズ固定のイラストやトレース的な活用に便利。 - プロンプト(Prompt)
生成したい要素を文章で指示する入力文。例:「猫 カフェ風 写真 高解像度」。 - ネガティブプロンプト(Negative Prompt)
出力から排除したい要素を指定する入力文。例:「ぼやけ、低解像度、手の歪み」。 - サンプリングアルゴリズム
画像をノイズから生成する際の計算方式。Euler、DPM++など複数の手法があり、結果の質や速度が変わる。 - ステップ数
ノイズを除去して画像を仕上げる回数。多いほど精緻になるが計算時間も増える。 - CFGスケール(Classifier-Free Guidance Scale)
プロンプトの指示をどの程度強く反映させるかの値。大きすぎると不自然、小さすぎると指示が反映されにくい。 - VRAM(Video RAM)
GPUに搭載された専用メモリ。解像度やモデルサイズが大きいほど多く必要となる。 - SDXL
Stable Diffusionの新世代モデル。従来より高解像度かつリアルな画像生成が可能だが、必要VRAM量も増える。 - SafeTensor形式
モデルファイルを安全に保存するフォーマット。pickle形式よりセキュリティリスクが低いとされる。 - CUDA/cuDNN
NVIDIA製GPUでディープラーニングを効率的に計算するためのソフトウェア環境。バージョンの整合性が重要。
原理をわかりやすく解説
Stable Diffusionは、ディープラーニング分野で近年注目を集める「拡散モデル(Diffusion Model)」の一種ですが、従来手法を大幅に効率化した潜在拡散モデル(Latent Diffusion Model, LDM)を採用しています。ここでは仕組みをステップごとにさらに詳細に掘り下げて解説します。
Step 1: 画像の圧縮(VAEエンコーダ)
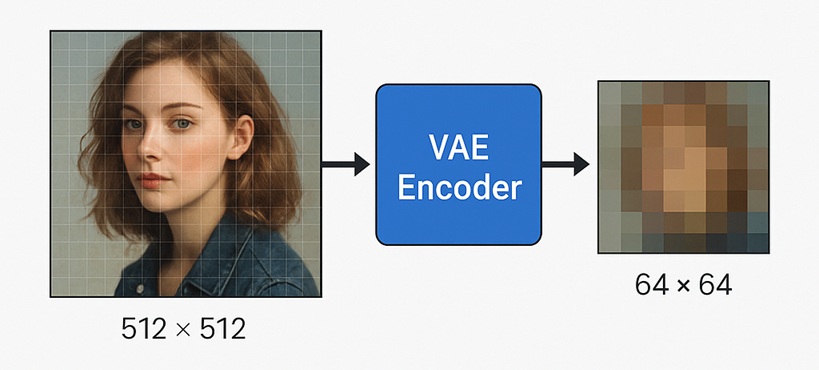
従来の拡散モデルはピクセル空間そのもの(解像度512×512なら26万以上の次元)で処理していたため、膨大なVRAMと計算時間を必要としました。
Stable DiffusionではVAE(Variational Autoencoder)を利用し、画像を低次元の潜在空間に圧縮します。例えば512×512の画像は64×64程度の潜在表現に変換され、次元数は数十分の一に減少します。これにより、学習や推論が一般的なGPU(8〜16GB VRAM)でも現実的に可能になります。
Step 2: 拡散過程(Forward Process)
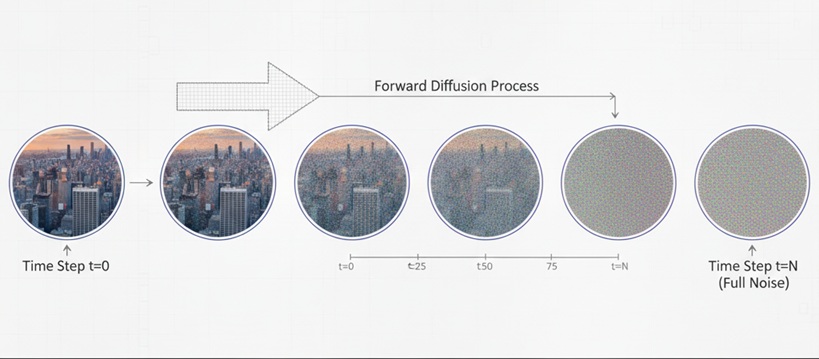
学習時には、圧縮された潜在表現にノイズを段階的に付与していきます。数百ステップに分け、最初は元画像に近い状態、最後は完全なガウスノイズへと変換されます。
この過程を「拡散」と呼び、モデルは「ノイズから元の潜在表現を推測する」ことを学びます。各ステップでのノイズの入り方は数学的に制御されており、ガウス分布に従う確率過程として定義されています。
Step 3: ノイズ予測器(U-Netアーキテクチャ)
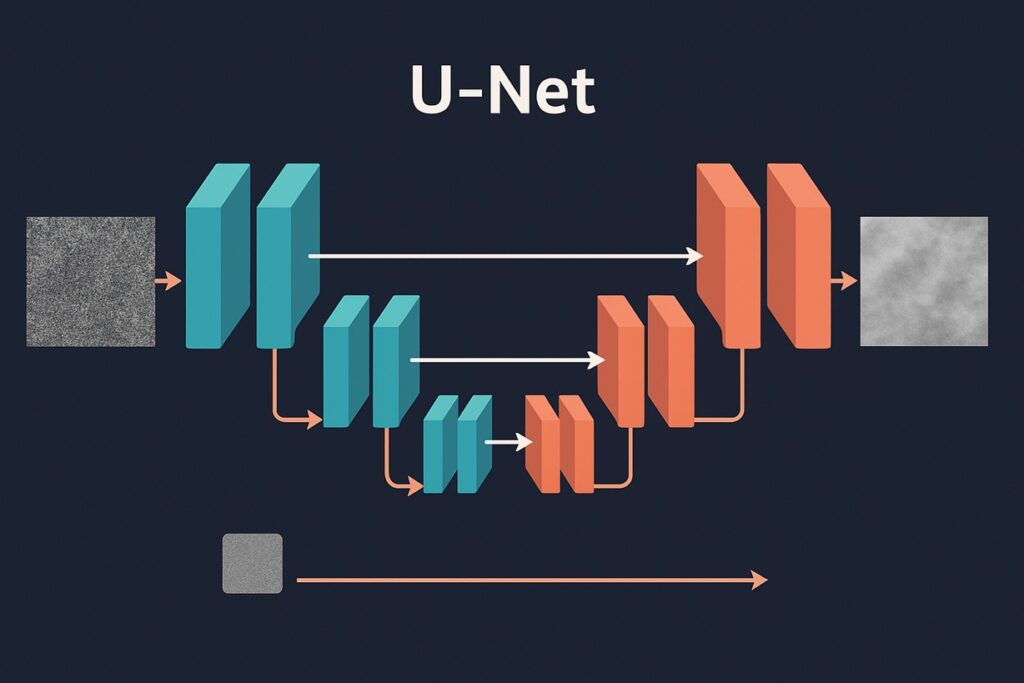
Stable Diffusionの心臓部はU-Net構造のニューラルネットワークです。U-Netは「エンコーダ」と「デコーダ」からなり、Skip Connection(特徴の横渡し)を通じて高解像度情報を保持しつつ、ノイズを効率的に推定できます。
U-Netの役割は「ある時刻tにおける潜在表現が、どの程度のノイズを含んでいるか」を推定することです。これにより、逆過程で不要なノイズを段階的に取り除くことが可能になります。
Step 4: テキスト条件付け(CLIPエンコーダ+Attention)
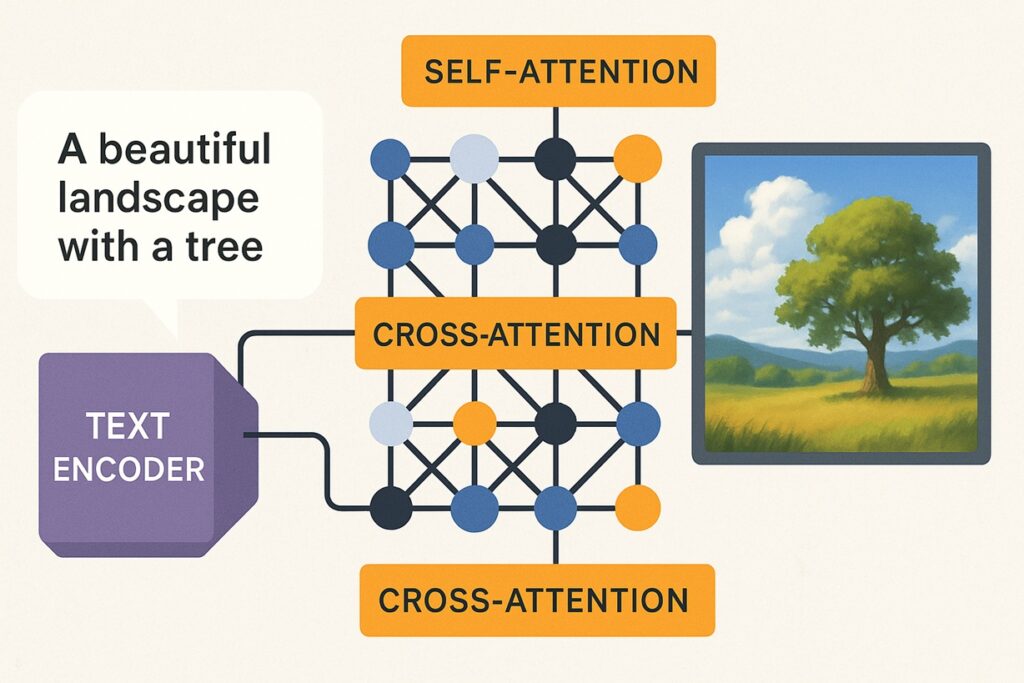
画像生成をテキストで制御する仕組みがテキスト条件付けです。
- 入力されたプロンプトはCLIP系テキストエンコーダでベクトル化されます。
- その埋め込みはCross-Attention層を通じてU-Netに渡されます。
ここで重要なのは2種類の注意機構です。
- Self-Attention:画像内の整合性を担保(例:人物の左右の手が一致する)
- Cross-Attention:テキストと画像の対応を担保(例:「青い空」と指示すれば青い空を反映)
これらが組み合わさることで、指示文の忠実度と画像の一貫性が両立します。
Step 5: 逆拡散過程(Generation)

生成時には、完全なノイズから出発します。U-Netが各ステップで「どの成分が不要なノイズか」を予測し、それを取り除くことで徐々に潜在表現が明瞭化していきます。数十〜百数十ステップを経て、意味を持った潜在画像が得られます。
Step 6: VAEデコーダによる画像復元

最後に、完成した潜在表現をVAEデコーダで画像空間に戻すことで、人間が視覚的に認識できる画像が生成されます。この復元過程で画質や色調が左右されるため、VAEの品質も出力に大きな影響を与えます。
●補助的要素とパラメータの意味
- CFGスケール(Classifier-Free Guidance)
条件付き予測と無条件予測の差を強調する係数。大きすぎると破綻、小さすぎると指示が弱まる。通常7〜12の範囲で調整。 - サンプリングステップ
ノイズを取り除く回数。少なすぎれば粗い結果、多すぎれば時間がかかりすぎる。20〜50程度が多用される。 - サンプラー方式
- Euler系:速度と安定性のバランス
- DPM++系:ディテール再現性が高い
●拡張と実用的工夫
- ControlNet:姿勢や線画を条件として追加することで構図の安定性を向上
- Hi-Res Fix(二段階生成):一度低解像度で生成し、再拡大してから再生成することで精細化
- LoRA / DreamBooth:追加学習でキャラクターや特定スタイルを強化
これらを組み合わせることで、高精度で一貫性のある画像生成が可能になりますが、VRAM使用量や生成時間も増えるため調整が必要です。
Stable Diffusionの理論的背景は次の学術論文に詳しくまとめられています。(出典:Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models, 2022 )
要するに、Stable Diffusionは
- 画像を潜在空間に圧縮して効率化し、
- ノイズを段階的に付与・除去する学習を行い、
- テキスト指示をCross-Attentionで反映し、
- 最終的に高解像度の画像を生成する
というステップで動作しています。
このプロセスは、限られたGPU資源でも実用的な画像生成を可能にする画期的な仕組みだと言えます。
●専門用語解説:
- U-Net
画像処理に広く使われるニューラルネットワークの構造。エンコーダで特徴を圧縮し、デコーダで再構築する仕組みを持ち、Skip Connectionによって細部の情報を保持できます。Stable Diffusionではノイズを正しく推定する中核として利用されています。 - Cross-Attention(クロスアテンション)
異なる情報源(テキストと画像潜在表現)の対応関係を学習する仕組み。テキストの「犬」という単語が、画像の犬の領域に影響を与えるように結びつける役割を果たします。 - Self-Attention(セルフアテンション)
画像内部の要素同士の関係を学習する仕組み。同じ画像内で「手」と「腕」の位置関係や一貫性を保つのに役立ちます。 - ResBlock(Residual Block)
ディープニューラルネットワークで使われる構造の一種。入力を一部スキップして出力に足し合わせることで、学習の安定性と表現力を高めます。Stable Diffusionでは時刻埋め込み情報を取り込み、ノイズ除去の進行度に応じた処理を行います。 - 時刻埋め込み(Timestep Embedding)
拡散過程の「今が何ステップ目か」という情報を数値ベクトルとして表現する仕組み。これによりモデルはノイズ除去の進行度を理解し、適切な処理を行えます。 - サンプラー(Sampler)
ノイズをどのように取り除いていくかの計算方式。EulerやDPM++などがあり、画像のシャープさや生成速度に大きく影響します。 - Hi-Res Fix(ハイレゾフィックス)
一度低解像度で生成した画像を拡大し、さらに追加ステップで再生成することで高精細化する手法。GPUメモリの負荷を抑えながら高品質な出力が得られます。 - DreamBooth
特定の人物やキャラクターを再現するための追加学習手法。少数の画像から個別のスタイルを学習させることができる反面、著作権や肖像権のリスクが伴います。
Stable Diffusionは無料?使用料の仕組み
Stable Diffusionは基本的に無償で利用可能なオープンソースの生成AIモデルです。しかし、無償で使えるのはあくまでソフトウェア部分であり、実際の運用には計算資源やサービス利用料といったコストが発生します。利用環境によって必要となる費用の性質が異なるため、導入前に具体的なコスト構造を理解しておくことが大切です。
ローカル環境での運用では、GPU性能が生成速度や出力品質に直結します。例えば、NVIDIAのRTX 3060クラスであれば512×512px程度の画像を数十秒で生成可能ですが、高解像度画像やバッチ生成には12GB以上のVRAMを備えたGPU(RTX 3080やA100など)が望ましいとされています。
加えて、16GB以上のRAMと数百GB規模のSSDが必要となることも少なくありません。これらは初期投資として数十万円規模に達する場合があり、無償利用といっても実用性を確保するには相応の設備投資が不可欠です。
一方、クラウドやオンラインサービスでは、初期投資を抑えつつ利用可能です。多くのサービスが無料枠を提供しており、例えば月数十回までの生成や512px程度までの解像度に制限されるケースがあります。さらに高解像度や商用利用を行う場合は、サブスクリプション(月額1,000円〜数千円程度)や従量課金制(1クレジットあたり数十円〜)に移行する仕組みが一般的です。
商用利用の観点では、モデルやサービス提供者が定めるライセンス条件に従う必要があります。Stable Diffusionの公式ライセンスでは、個人利用や小規模利用に関しては原則自由とされていますが、一定規模以上の商用プロジェクトではエンタープライズ契約を求められることがあります。さらに、生成物の公開や二次利用に関しては、再学習への利用可否、利用者による責任範囲、禁止される分野(アダルト、ヘイトコンテンツなど)が明記されています。
無料版と有料版の比較表
| 項目 | 無料版(ローカル環境 / 無料枠サービス) | 有料版(クラウド / サブスク / エンタープライズ) |
|---|---|---|
| 初期費用 | GPUやPCを保有していれば追加費用なし。ただしGPU購入時は10万〜数十万円規模 | 初期投資なし。月額契約や従量課金で利用開始可能 |
| 実行環境 | ローカルPCに依存。GPU性能がボトルネックになりやすい | クラウドGPU環境で安定稼働。高性能GPUを即時利用可 |
| 利用回数制限 | サービスによっては月数十回まで、解像度制限あり | 無制限に近い利用が可能。高解像度(768px〜、4K対応)も選択可 |
| カスタマイズ性 | 非常に高い(LoRA、拡張機能、独自学習可能) | サービス依存。高度なカスタムは制限される場合あり |
| 商用利用 | 制限あり。規模が大きいとエンタープライズ契約必須 | 契約範囲内で商用利用可。サポートやSLAが付随することも多い |
| セキュリティ / プライバシー | ローカルで閉じた利用なら高い。クラウド無料枠は事業者依存 | クラウドベンダーのセキュリティ基準に依存。ログ・監査体制あり |
| ランニングコスト | 電気代、GPU劣化コスト | 月額1,000円〜数万円、または従量課金(例:1クレジット数十円〜) |
まとめると、Stable Diffusionの「無料」という言葉はソフトウェアそのものを指すに過ぎず、運用環境や利用目的に応じてGPU購入費、クラウド利用料、ライセンス契約費用といった現実的なコストが発生します。研究機関や企業においては導入前に公式ライセンス文書を必ず確認し、費用と利用規約を照らし合わせて適切な利用形態を選定する必要があります(出典:Stability AI公式ライセンス)。
弱点とリスクの実態
Stable Diffusionは高品質かつ柔軟に画像を生成できる強力なツールですが、その内部構造や利用環境に起因する「技術的な弱点」と「利用上のリスク」が存在します。これらを正しく理解せずに使うと、生成結果の不自然さや法的トラブル、セキュリティ事故につながる恐れがあります。
技術面での弱点
- プロンプトへの過敏さ
Stable Diffusionは入力文(プロンプト)のわずかな違いに敏感に反応します。単語の順序や強調記号の位置によって、出力される構図やスタイルが大きく変化します。そのため「狙った通りの画像が安定して得られない」という再現性の低さが課題となります。 - ディテール表現の破綻
手指の本数や関節の配置、文字の形状など、細かい要素の描写では破綻が生じやすい傾向があります。特に複雑なポーズや多人数構図、文章を含む画像生成では、精度不足が目立ちます。 - 学習データ依存による偏り
モデルは学習データに強く依存しているため、特定の画風や文化圏の表現に偏りやすい傾向があります。例えば西洋的なイラストや写真スタイルは得意でも、他地域の文化的要素やマイナーなモチーフは再現精度が低い場合があります。 - 高解像度生成の負荷
高解像度(例:1024px以上)の画像を生成する際はVRAMを大量に消費します。一般的なコンシューマGPU(8〜12GB)では処理が途中で停止することもあり、現実的に安定運用するには24GB級以上のGPUが必要になるケースもあります。 - 追加学習の副作用
LoRAやDreamBoothによる追加学習は特定のスタイル再現に有効ですが、過学習が起きると元データをそのまま再現してしまう「リーク」のリスクがあります。これは倫理的にも法的にも重大な問題を引き起こしかねません。
利用上のリスク
- 外部拡張のセキュリティリスク
非公式拡張や外部モデルを導入すると、互換性問題やマルウェア混入のリスクが発生します。特に.ckpt形式のモデルには任意コードを仕込める余地があるため、近年は安全性を高めた.safetensors形式が推奨されています。 - 権利侵害のリスク
生成物が既存キャラクター、ブランドロゴ、実在人物に酷似する場合、著作権・商標権・肖像権の侵害とみなされる可能性があります。利用者の意図に関係なく「似ている」と評価されればトラブルの火種になります。特に商用利用では訴訟リスクが高まります。 - 規制・ガイドライン違反
成人向けや暴力的な表現、未成年を想起させるコンテンツは、多くのサービスで禁止されています。違反すればアカウント停止や作品削除につながるだけでなく、社会的信用の失墜にも直結します。 - 再利用と責任の所在
一部サービスでは、生成物が学習に再利用される可能性があります。利用者が生成物を外部公開する際、二次利用の範囲や責任の所在を理解していないと、思わぬ形で作品が使われてしまうリスクもあります。
Stable Diffusionは「万能な画像生成ツール」ではなく、技術的制約と社会的リスクを常に内包しています。利用者は次の3点を意識する必要があります。
- 技術的な限界を把握し、出力を過信しないこと
- ライセンスと規約を精読し、商用利用では法務リスクを管理すること
- セキュリティと倫理性を担保する体制を整えること
これらを徹底してはじめて、安全かつ持続的にStable Diffusionを活用できるといえます。
どこが危険かを分析
Stable Diffusionを利用する上で直面しやすいリスクは、多岐にわたります。技術的背景や社会的な影響を理解することで、ユーザーは優先的に取り組むべき対策を把握できます。
以下では、リスク領域ごとに典型的な事例や原因、基本的な対策を整理します。実際の利用シーンに応じてリスクを具体的にイメージできるようにすると、より現実的な対応策を立てることが可能です。
リスク早見表
| リスク領域 | 典型的な発生場面 | 主な原因 | 基本対策 |
|---|---|---|---|
| 著作権・商標・肖像権 | 公開・商用化 | 既存作品や人物に酷似 | 参照制限、モデル選定、権利確認 |
| 倫理・有害表現 | プロンプト設計 | 不適切語句や曖昧指示 | 禁止語管理、レビュー体制 |
| プライバシー | 実在人物の生成 | 同意のない人物模倣 | 実在名回避、公開範囲制御 |
| サイバーセキュリティ | 拡張導入・DL | 非公式配布物の混入 | 公式入手、SafeTensor、スキャン |
| 運用安定性 | 大量生成・高負荷 | VRAM不足、依存不整合 | スペック確認、環境固定 |
| コンプライアンス | サービス利用規約違反や規制抵触 | 規約違反、法令無理解 | 規約精読、用途審査、記録 |
●著作権や商標、肖像権に関わるリスクは、最も身近で深刻なトラブルの原因となりやすい領域です。生成された画像が既存のキャラクターやブランドロゴ、あるいは著名人に酷似した場合、意図せずとも権利侵害とみなされる恐れがあります。
これは日本国内の著作権法や各国の知的財産権法に直結する問題であり、商用利用時には特に注意が必要です。例えば、文化庁が公開している著作権に関する解説(出典:文化庁 著作権テキスト)は、利用者が理解を深める上で有用です。
●倫理的リスクについても軽視できません。プロンプト設計時に不適切な語句を入力すると、差別的、暴力的、あるいは性的に過激な表現を含む画像が生成される場合があります。こうした画像を公開した場合、利用者個人の信用を損なうだけでなく、プラットフォーム規約違反によりアカウント停止などの処分を受ける可能性があります。事前に禁止語リストを管理し、出力物をレビューする体制を整えることが、リスクを抑える鍵となります。
●プライバシー領域では、実在人物を同意なく模倣した生成が大きな問題となります。SNSや公開データセットに含まれる人物画像をもとにした生成物は、本人の権利を侵害する可能性が高く、肖像権や個人情報保護の観点から問題視されます。特に、未成年を想起させる生成物については、社会的・法的に強い規制対象となることが多いため、実在名や具体的な特徴を含むプロンプトは避けるべきです。
●サイバーセキュリティの観点では、非公式の拡張機能やモデルファイルの導入が危険要因となります。インターネット上で配布されるモデルの中には、悪意あるコードが埋め込まれている可能性があり、実行環境の乗っ取りや情報漏洩につながるリスクがあります。モデルを導入する際は、公式リポジトリや信頼できる配布元から入手し、SafeTensor形式など改ざん検出が可能な形式を選ぶことが推奨されます。
●さらに運用安定性にもリスクがあります。大量の画像を一度に生成するとVRAM不足や依存関係の不整合が発生し、動作停止やエラーを招く場合があります。事前に利用環境のスペックを確認し、バージョン固定や環境管理ツールを活用することで安定性を維持しやすくなります。
●最後に、コンプライアンスの問題も見逃せません。各サービスには利用規約が定められており、これを理解せずに利用すると契約違反や法令違反につながります。例えば、あるサービスでは商用利用に制限を設けていたり、生成物の再配布を禁止していたりします。利用前に必ず規約を精読し、用途が適法かを審査し、記録を残すことが責任ある利用につながります。
このように、Stable Diffusionを安全に使うためには、単に技術を学ぶだけでなく、法的・倫理的・社会的なリスクを体系的に理解し、予防策を講じることが欠かせません。
Stable Diffusion 危険性と安全な活用法
●このセクションで扱うトピック
- 安全性を確保する方法
- Stable Diffusion web UIの危険性の注意点
- 利用規約で確認すべき点
- 規制と法的リスク
- Stable Diffusionが開かない時の解決策
- Stable Diffusion 危険性のまとめと指針
安全性を確保する方法
Stable Diffusionを安心して活用するためには、導入段階の技術的対策と、日常的な運用ルールの両面から管理体制を整えることが欠かせません。特に生成AIは常に新しい拡張やモデルが公開され続けているため、適切な安全対策を取らなければセキュリティや法的リスクが高まります。
導入時には、必ず公式サイトや信頼できるリポジトリからダウンロードすることが前提です。特にモデルファイルはSafeTensor形式を優先し、改ざんリスクを最小化します。ダウンロード後にはウイルススキャンを行い、実行前に安全性を確認することも推奨されます。拡張機能は便利である一方、開発者が不明確なものやソースが公開されていないものはセキュリティリスクとなるため導入を避けるべきです。また、外部通信は基本的に無効化し、WebUIを外部公開する設定はデフォルトでオフにしておくことで、不正アクセスの危険性を大幅に減らせます。
運用段階では、センシティブなプロンプトを避け、ネガティブプロンプトを活用して不要な要素の混入を防ぐ工夫が求められます。生成した画像は必ず人間の目で確認し、公開前には著作権や肖像権の観点から問題がないかを点検します。また、生成ログや利用したモデルのバージョン、適用したLoRAや拡張の情報を記録しておくことで、万一トラブルが生じた場合にも説明責任を果たしやすくなります。
法人利用ではさらに高度なガバナンスが求められます。例えば、用途ごとに利用審査を行い承認記録を残すこと、利用モデルやLoRAのライセンス台帳を整備して契約条件を明示すること、そして社内規程やガイドラインを定めて従業員の利用行動を管理することが鍵となります。これらを体系的に整えることで、利用者個人のリスクを超えて、組織全体のコンプライアンスを確保できます。
(出典:情報処理推進機構 IPA「安全なウェブサイトの作り方」)
Stable Diffusion web UIの危険性の注意点
Stable Diffusionを利用する際、最も広く使われているツールの一つが「Stable Diffusion WebUI(AUTOMATIC1111版が代表的)」です。これはブラウザベースのユーザーインターフェースで、コマンドラインの知識がなくても直感的に操作でき、生成パラメータの調整や追加機能の導入を容易にします。
特に次のような利点があります。
- 直感的な操作性:プロンプト入力欄、スライダー式のパラメータ調整、プレビュー表示など、初心者でも扱いやすいUI。
- 拡張性:ControlNet、LoRA、DreamBoothなどの拡張機能をGUIから導入可能。
- プラグイン形式の機能追加:外部のカスタムスクリプトやアドオンを組み込めば、画像編集や動画生成など幅広い用途に対応。
しかし、この利便性の裏にはセキュリティ面でのリスクが潜んでいます。以下にWebUI特有の危険性と注意点を整理します。
1. 外部拡張機能によるセキュリティリスク
WebUIはコミュニティ主導で拡張が盛んに行われていますが、非公式配布の拡張や学習済みモデルにはマルウェアが仕込まれる危険性があります。特に.ckpt形式のモデルファイルは任意コードを実行できる構造のため、信頼できる配布元からのみ入手することが重要です。近年は安全性を高めた.safetensors形式が推奨されています。
2. ネットワーク公開による侵入リスク
WebUIは標準でローカル環境での利用を前提としていますが、利便性を求めて外部公開設定を行うと、認証なしでアクセスされる危険性が生じます。これはポートスキャンや不正アクセスの対象になりやすく、実際に外部公開した環境が攻撃を受けた事例も報告されています。VPNや閉域網を利用し、必ずパスワード認証・二段階認証を導入すべきです。
3. 自動スクリプト・DLLの脆弱性
WebUIには便利な自動化スクリプトや外部DLLの導入機能がありますが、権限管理が不十分なまま利用すると不正コード実行のリスクが高まります。管理者権限での実行を避け、最低限の権限で運用することが推奨されます。
4. モデルライセンス違反のリスク
WebUI経由で簡単にモデルを追加できるため、利用者がライセンスを確認せずに商用利用してしまうケースが懸念されます。Stable Diffusion公式ライセンス(Stability AIの利用規約)や各モデルの作者が提示する条件を精読し、商用利用が認められているかどうかを確認しなければなりません。違反すると、利用停止や法的トラブルに発展する恐れがあります。
5. ログ・アクセス履歴の管理不足
不審な挙動や不正アクセスを早期発見するには、WebUIのログやアクセス履歴を保存・監視することが不可欠です。監視を怠ると、外部から侵入されても気付かず、情報漏洩やリソースの悪用につながる可能性があります。
Stable Diffusion WebUIは初心者から研究者まで幅広く使われている強力なツールですが、利便性の裏にセキュリティとライセンス上のリスクを抱えています。
- 拡張機能・モデルは信頼できる配布元から取得すること
- 外部アクセスはVPNや認証を必須とし、無防備な公開を避けること
- 商用利用前には必ずライセンス条項を再確認すること
この3点を徹底することで、安全かつ持続的にWebUIを活用できます。
利用規約で確認すべき点
Stable Diffusionをサービス型で利用する場合には、必ず利用規約とAcceptable Use Policy(AUP)を精読することが求められます。これらの文書には、生成可能なコンテンツの範囲や利用者の責任が明記されており、違反するとアカウント停止や利用制限といった重大な措置を受ける可能性があります。
公式の利用規約はStability AI Terms of Service、AUPはStability AI Acceptable Use Policyから確認できます。これらの一次情報を参照することで、利用者が直面し得るリスクを正しく理解できます。
AUPでは、性的表現や児童に関連する有害コンテンツ、差別的・ヘイトスピーチに該当する表現、暴力や違法行為を助長する内容などが禁止されています。さらに、提供されている安全機構を意図的に回避する行為も重大な違反とみなされます。こうした禁止事項に抵触すると、サービスからの即時停止や出力データの削除、さらには法的措置につながる危険があります。
また、利用規約には生成物の権利帰属についての条項も含まれています。多くの場合、出力された画像の権利は利用者に帰属するとされていますが、利用環境によってはサービス提供者側が再学習や検証のために利用できる場合があります。商用利用を行う際には、出力物に対する責任を利用者が全面的に負うことが明記されており、第三者の権利を侵害した場合には法的責任を免れません。
APIを用いる場合には、APIキーの管理責任が利用者に課されています。万が一キーが漏洩して不正利用があった場合でも、発生した損害はユーザーが負担しなければならない可能性があります。さらに、規約では仲裁条項や準拠法・裁判管轄地についても規定されており、多くの場合は英国法や米国法に基づいて処理されるため、利用者の居住国とは異なる法制度が適用される点にも注意が必要です。
加えて、Stability AIの公式ドキュメントでは、一定規模を超える商用利用にはエンタープライズ契約が必要であることが明示されています。これは単なる料金面の問題ではなく、追加的な義務や責任が発生する可能性を意味します。そのため、研究利用と商用利用とでは同じモデルであっても適用されるルールが異なるという点を理解しておくことが不可欠です。
要するに、Stable Diffusionの利用はオープンかつ柔軟である一方で、規約に違反すればサービス利用の停止や法的責任に直結します。禁止されているコンテンツの範囲、権利の帰属、API管理の責任、そして商用利用時の追加契約の有無といった点を確認し、規約に則った利用を徹底することが安全な活用への前提条件となります。
規制と法的リスク
Stable Diffusionを含む生成AIは急速に普及しており、各国や地域で法規制や指針の整備が進められています。欧州連合(EU)ではAI法案(AI Act)の審議が進み、透明性確保やリスク管理、未成年保護といった要件がAIサービスに求められるようになっています。日本でも総務省や経済産業省がガイドラインを策定しており、AI利用における倫理や法令遵守の重要性が強調されています(出典:総務省「AI利活用ガイドライン」)。
●倫理的側面においては、透明性と説明責任が重視されています。出力結果にラベルを付与してAI生成であることを明示することや、利用者が生成物の作成過程を説明できるようにログを残すことは、社会的信頼を維持するための重要な施策です。また、医療、法務、金融といったセンシティブな分野で利用する場合は、専門家レビューを導入し、誤った情報が重大な被害を生じないようにすることが推奨されています。
●著作権や肖像権の観点でもリスクがあります。既存作品を参照しすぎた出力や、実在人物に酷似した生成物は、権利侵害に問われる可能性があります。Stable Diffusionの公式ドキュメントでは、禁止領域に該当する生成や安全機構の回避を行った場合、出力が削除されたりアカウントが停止されたりする措置が取られることが明記されています。こうした規定を理解せずに利用すると、利用者が意図せず法的責任を負う可能性があります。
●企業利用の場面では、コンテンツモデレーション体制を整備することが信頼性を大きく左右します。具体的には、生成物の審査を行う専門部署の設置、外部からの問い合わせ窓口の明確化、異議申立てがあった場合に備えた対応プロセスの設計が求められます。これにより、社会的批判や法的リスクを最小限に抑えつつ、責任あるAI活用を進めることが可能になります。
以上のように、Stable Diffusionの利用には国内外の規制を常に把握し、倫理・法的観点からのリスクを意識した運用体制を築くことが不可欠です。
Stable Diffusionが開かない時の解決策
Stable Diffusionを起動しようとしてもエラーが発生するケースは珍しくなく、その多くは環境依存の不整合や設定の不備が原因です。とくにPythonのバージョン、依存ライブラリ、GPU環境、WebUIの競合設定などが典型的な要因となります。以下では、代表的な症状ごとに原因と対処法を整理しました。初めて扱う方でも理解しやすいよう、エラーメッセージの意味や解決の流れを具体的に解説します。
●症状別リスクと主な対処法
| 症状メッセージ例 | 想定原因 | 主な対処 |
|---|---|---|
| Couldn’t launch python | Python未認識・パス不整合 | Pythonの再インストールとパス設定の明示 |
| Torch is not able to use GPU | ドライバ不整合・VRAM不足 | GPUドライバ更新、CUDA対応版確認、設定見直し |
| Error running command | 依存破損・権限不足 | 仮想環境再構築、必要権限で再実行 |
| RuntimeError: Cannot add middleware… | WebUIの旧版・拡張競合 | WebUI更新、拡張の一時無効化 |
| No python at〜 | パス断絶・配置変更 | インストール先を再指定し再構成 |
●よくある不具合の背景と解説
Python関連のエラーは、特に初心者が遭遇しやすい問題です。Stable DiffusionはPython環境上で動作するため、システムがPythonを正しく認識できないと実行そのものが止まります。Windows環境ではPATH設定が適切でないことが多く、インストール直後に「Couldn’t launch python」と表示される場合があります。この場合、公式のPython配布元から再インストールし、PATHを手動で設定するのが確実です(出典:Python公式サイトダウンロード)
GPUに関するエラーは、NVIDIAドライバやCUDAとの互換性が原因になることが一般的です。Stable Diffusionは大量のVRAMを消費するため、モデルや解像度によってはGPUが対応できず「Torch is not able to use GPU」と表示されることがあります。最新のドライバへ更新し、必要であればCUDAの対応バージョンを確認することが解決への近道です。
依存関係の破損や権限不足が原因で「Error running command」と出る場合は、仮想環境の再構築を行うのが有効です。Anacondaやvenvで環境を作り直すと、パッケージ間の衝突が解消されやすくなります。
WebUIに関するエラーは、拡張機能の競合や古いバージョンの残存が原因で発生します。「RuntimeError: Cannot add middleware…」はその典型で、WebUI本体を最新の安定版に更新し、問題がある拡張を一時的に無効化すると改善することが多いです。
「No python at〜」といったパスエラーは、Pythonの配置場所が変更されたり、複数バージョンが混在した場合に起こります。インストール先を明示的に指定し直し、必要なら再構成することが求められます。
●効率的なトラブルシューティングの進め方
多くの不具合は、最新の安定版に更新し、仮想環境を作り直すことで改善します。特にログを保存してエラーメッセージを逐一確認することが、原因の切り分けを迅速化する鍵です。実行環境を複製してテストする方法も効果的で、問題の再現性を確認しながら修正を進められます。
また、公式ドキュメントや開発元のGitHubリポジトリでは、既知のエラーと修正方法が公開されているため、エラーメッセージをそのまま検索して参照すると解決策が見つかりやすいです。初学者にとっては敷居が高く感じられるかもしれませんが、段階的に切り分ける姿勢が安定稼働への近道になります。にくい場合は、要素技術を固定したテンプレート環境をバックアップしておくと復旧が容易です。
Stable Diffusion 危険性のまとめと指針
本記事のまとめを以下に列記します。
- 著作権や肖像権への配慮は公開前点検で担保する
- 禁止領域の生成は避けサービス規約を常に再確認する
- 公式配布とSafeTensor形式を基本に導入する
- WebUIは外部公開を避け最小権限と認証を徹底する
- プロンプトは曖昧さを排しネガティブ指定も併用する
- 生成物は人の目でのレビューを必ず経由させる
- モデルやLoRAの商用可否を案件単位で記録する
- 出力ログとモデル版数を残し説明可能性を確保する
- 高負荷時はVRAM要件と依存整合性を再点検する
- 代表的な起動エラーは表の手順で解消を試みる
- 倫理とブランドセーフティ基準を運用文書化する
- 企業利用は承認フローとモデレーション体制を整える
- 規制動向と公式ドキュメント更新を定期確認する
- 大規模商用は契約条件と責任範囲を事前精査する
- リスク早見表で場面別の対策優先度を明確化する


コメント